大数据Hadoop集群下的离线数据存储与挖掘分析架构 数据处理与存储支持服务详解
在大数据时代,面对海量数据的存储与深度分析需求,基于Hadoop生态系统的离线数据处理架构已成为企业级数据基础设施的核心。本章将深入探讨Hadoop集群环境下,离线数据的存储体系、挖掘分析架构以及关键的数据处理与存储支持服务。
一、Hadoop集群离线数据存储架构
Hadoop分布式文件系统(HDFS)构成了离线数据存储的基石。其高容错、高吞吐量的特性,使其能够稳定存储PB级别的原始数据、清洗后的数据以及各类中间结果。通常,存储架构采用分层设计:
- 原始数据层:直接接入来自日志、数据库、物联网设备等的原始数据,通常以原始格式(如文本、序列文件)存储。
- 清洗整合层:对原始数据进行清洗、去重、格式标准化等预处理后存储,为后续分析提供高质量数据源。
- 轻度汇总层/数据仓库层:根据业务主题,对数据进行轻度聚合或构建维度模型,存储在如Hive表中,支持灵活的交互式查询。
- 数据集市/应用数据层:为特定分析场景或应用(如报表、机器学习)高度聚合和优化的数据。
二、离线数据挖掘与分析架构
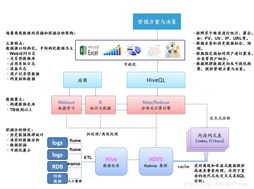
以MapReduce、Spark等计算框架为核心,构建了强大的离线批处理分析能力。典型的分析架构遵循“数据管道”模式:
- 数据采集与接入:使用Flume、Sqoop等工具将数据从各源头稳定导入HDFS。
- 数据计算与处理:这是核心环节。利用MapReduce进行海量数据的复杂ETL(提取、转换、加载);或使用Spark及其MLlib库,凭借内存计算优势,进行迭代式计算和机器学习模型训练,效率更高。计算任务通常由YARN等资源调度器统一管理。
- 分析与挖掘应用:基于处理后的数据,业务分析师通过Hive、Spark SQL进行即席查询;数据科学家使用Spark MLlib、Mahout等构建和运行挖掘模型(如聚类、推荐、预测)。
- 结果输出与服务:分析结果可写回HDFS,或导出至关系型数据库、NoSQL数据库,供前端报表系统、推荐引擎等应用调用。
三、关键的数据处理与存储支持服务
为确保整个架构高效、稳定、易用,一系列支持服务不可或缺:
- 资源管理与调度服务:YARN作为Hadoop 2.0后的核心组件,负责集群资源(CPU、内存)的统一管理和调度,允许多个计算框架(如MapReduce, Spark)共享集群资源,提高利用率。
- 数据仓库与SQL化服务:Apache Hive将结构化的数据文件映射为数据库表,并提供HiveQL查询语言,将复杂的MapReduce程序简化为类SQL语句,极大降低了数据分析门槛。其元数据存储在独立数据库(如MySQL)中。
- 协调与元数据管理服务:ZooKeeper提供分布式协调服务,保障集群高可用,管理配置信息、命名服务等。对于更上层的数据治理,Apache Atlas等工具可提供数据血缘、分类和集中式元数据管理。
- 工作流调度与监控服务:Apache Oozie或Azkaban等工具用于编排和调度复杂的、依赖关系的Hadoop作业(如Hive、Spark、Sqoop任务)形成工作流,实现自动化数据处理流水线。需配合集群监控工具(如Ambari, Grafana+Prometheus)监控集群健康状态与作业性能。
- 数据格式与压缩服务:合理使用列式存储格式(如ORC, Parquet)与压缩算法(如Snappy, LZO),能极大提升存储效率和查询性能,是优化存储成本的关键。
一个成熟的大数据Hadoop离线处理架构,是存储、计算、调度、管理服务的有机整合。它通过HDFS实现海量数据的可靠存储,依托YARN、Spark等框架完成高效计算与深度挖掘,并借助Hive、Oozie、ZooKeeper等一系列支持服务,将强大的底层能力封装为稳定、易用的数据生产力平台,从而为企业决策、用户洞察和智能应用提供坚实的数据支撑。随着云原生和存算分离趋势的发展,此架构仍在持续演进,但其核心思想与服务体系依旧具有重要指导价值。
如若转载,请注明出处:http://www.nuchonglianmeng.com/product/45.html
更新时间:2026-06-19 19:01:57