Pulsar vs. Kafka 以Segment为中心的架构及其对数据处理与存储支持服务的启示
在当今的大数据与实时计算领域,Apache Pulsar和Apache Kafka作为两大核心消息流平台,其设计哲学与架构选择深刻影响着企业的数据处理和存储支持服务。特别是两者在“以Segment为中心”的架构理念上的异同,成为了理解其性能、可扩展性和运维复杂性的关键。本文旨在深入探讨这一架构特性,并分析其对构建健壮数据处理与存储服务体系的支撑作用。
核心架构理念:Segment的引入
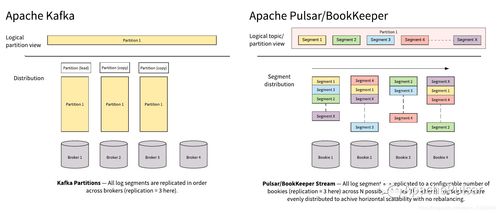
传统消息队列或早期流处理系统常将主题(Topic)视为一个连续的、不可分割的日志。而“以Segment为中心”的架构,其核心思想是将一个主题的持久化日志在物理上分割成多个更小、更易管理的部分——即Segment(在Kafka中称为Log Segment,在Pulsar中称为Ledger Segment)。这种设计带来了根本性的变革:
- 存储与计算的解耦:Segment作为独立的存储单元,使得存储层可以从服务层(Broker)中抽象出来。Pulsar将这一理念贯彻得更为彻底,其分层架构明确分离了无状态的服务层(Brokers处理消息传递)和持久的存储层(BookKeeper集群以Segment形式存储数据)。Kafka虽然依赖其Broker节点本地磁盘存储Segment,但其底层同样基于Segment文件进行日志管理。
- 无限的横向扩展与独立伸缩:由于Topic被划分为多个Segment,新数据可以写入新的Segment,而旧的Segment可以被独立地归档、迁移或删除。这为存储容量的无限水平扩展和独立于计算资源的存储伸缩提供了可能。Pulsar借助BookKeeper,可以轻松地将旧的Segment从高性能存储(如SSD)卸载到低成本对象存储(如S3),实现分层存储。
- 并发的读写与高效的数据管理:多个Segment可以支持更高程度的并行读写操作。例如,在数据回溯(Backfill)或追赶消费(Catch-up Consumption)时,可以并行读取多个历史Segment,极大提升了吞吐量。Segment作为独立的清理、压缩和保留策略单元,使得数据生命周期管理更加精细和高效。
Pulsar与Kafka的实现对比
尽管共享“Segment”这一核心概念,但Pulsar和Kafka在具体实现和由此带来的服务支持能力上存在显著差异:
- Pulsar的Segment(Ledger)与分层架构:
- 存储完全解耦:Pulsar的Segment(在BookKeeper中称为Ledger)完全存储在独立的BookKeeper存储集群中。Broker节点不持有数据,仅提供消息路由和服务发现。这种彻底的分离带来了极高的弹性——Broker可以快速故障恢复或无状态扩展,存储层可以独立进行扩缩容和优化。
- Segment即服务边界:每个Segment(Ledger)在BookKeeper中被复制到多个存储节点(Bookie)上,其生命周期(创建、密封、删除)由Broker精细控制。这为Pulsar原生支持多租户、命名空间级别的存储隔离和配额管理奠定了坚实基础。
- 对存储支持服务的直接影响:这种架构使得Pulsar能够原生、无缝地集成分层存储(Tiered Storage)。冷数据的Segment可以被透明地卸载到对象存储,而对客户端完全无感知。这极大地降低了长期数据保留的成本,是构建大规模历史数据平台的理想选择。
- Kafka的Log Segment与本地存储:
- 存储与计算耦合:Kafka的Segment是存储在Broker本地磁盘上的物理文件序列。每个Broker负责其分配到的分区(Partition)的所有Segment的读写和存储。这种设计简单高效,延迟极低,因为数据访问是本地化的。
- Segment作为本地文件管理单元:Kafka依赖操作系统的页缓存和高效的顺序I/O来保证性能。Segment的滚动、索引和清理策略是Kafka高性能的关键。存储的扩展与Broker节点绑定,扩容数据分区通常需要重新分配数据,过程相对复杂。
- 对存储支持服务的直接影响:Kafka本身不原生支持与远程/对象存储的透明分层。虽然可以通过如Kafka Connect等工具将数据归档到S3,或使用Confluent的特定功能,但这并非核心架构的一部分,可能增加运维复杂性。其存储支持更侧重于通过增加Broker节点和调整本地存储配置来进行横向扩展。
对数据处理与存储支持服务的意义
以Segment为中心的架构,特别是Pulsar所代表的完全解耦模式,为现代数据处理和存储支持服务带来了深远影响:
- 服务可用性与运维简化:存储与计算的分离允许两者独立故障恢复、升级和扩缩容。在Pulsar中,替换一个Broker几乎瞬时完成,不影响数据持久性;存储层(Bookie)可以独立进行硬件升级。这大幅提升了整个服务的可用性和运维灵活性。
- 成本优化与弹性存储:通过分层存储,热数据保存在高性能介质以满足低延迟需求,而海量冷数据可自动迁移至低成本对象存储。这实现了存储成本的阶梯式优化,特别适合需要长期合规性存储或进行大规模历史数据分析的场景。
- 云原生与多租户支持:Segment作为独立的资源单元,便于在云环境中进行计量、配额和隔离。Pulsar的架构天生适合云原生部署和强大的多租户支持,能为不同团队或应用提供隔离的、带有服务质量保证(QoS)的消息和存储服务。
- 统一的数据服务层:这种架构促进了流存储(Stream Storage)概念的形成,即消息系统不再仅仅是管道,而是一个可重放、可长期保留的可靠存储系统。Pulsar的“流原生”设计使其能够统一实时处理和批处理的数据源,简化了Lambda或Kappa架构的数据基础设施。
结论
Apache Pulsar和Apache Kafka都通过“以Segment为中心”的架构解决了大规模数据流的核心存储问题。Kafka的方案更注重简单性和极致的本地I/O性能,在计算与存储紧密协同的场景下表现出色。而Pulsar通过将Segment抽象为完全独立的存储单元,并实现服务与存储的彻底分离,构建了一个在弹性、可扩展性、多租户和成本优化方面更具优势的平台,尤其适合于构建企业级、云原生的统一数据处理和存储支持服务。选择何者,最终取决于企业在性能、运维复杂度、长期成本以及未来架构演进路线上的具体权衡。
如若转载,请注明出处:http://www.nuchonglianmeng.com/product/46.html
更新时间:2026-06-19 09:24:18